2020. 5. 9. 23:33ㆍAI/RL
Chapt 2의 제목 멀티 암드 밴딧(Multi-armed Bandits, MAB)
MAB 이전에 먼저 Bandit 문제가 어떤 문제인지 알아보자.
Bandit Problem(선택문제) : 오직 하나의 상태만 다루는 강화학습 문제
MAB는 강화학습으로 분류되지 않지만 강화학습의 특징에 해당하는 탐색과 활용(Exploration & Exploitation) 을 다루고 있는다는 점에서 소개한다.
강화학습은 다른 학습 방법(ML,DL)과 다르게 "이렇게 해야한다" 알려주는것(instruct, 지침)이 아니고 자신이 경험해보고 평가하면서 뭐가 좋은지 아는 방식(Evalutation, 평가)이다. 이를 위해서는 직접적인 탐색이 필요하다.
먼저 MAB의 역사를 통해 MAB가 어떤 컨셉을 가지고 있는지 알아보자.
MAB는 카지노에 있는 여러개의 슬롯머신(Bandit) 중 어떤 슬롯머신의 손잡이(Arm)을 내려야
최적의 수익을 얻을 수 있을까? 하는 문제에서 역사가 시작되었다.
카지노의 고객들은 특정 슬롯 머신의 수익률이 좋다는 사실을 경험적으로 알아내었다.
우리는 이제 어떠한 전략으로 투자해야할까?
선택문제 (Bandit problem)
전략을 세우기에 앞서서, 용어를 정의하고 가자.
슬롯 머신 손잡이를 내리는 행동을 { 행동, Action } 이라고하자
슬롯 머신 손잡이를 내려서 받는 보상을 { 보상, Reward } 라고 하자
그리고 처음 시점부터 지금까지 행동을 「선택」 하면서 받은 누적 보상을 { 가치, Value } 라고 하자.
- 이 때 가치는 현재 시점에서는 미래 보상을 알 수 없으므로, 「확률의 기대값 E{}」 를 사용하고 이 미래에 받는 보상의 기대값의 평균이 Value가 된다. MAB에서는 이 확률이 시불변 확률분포를 따른다고 한다. ( Stationary Probability Distribution )
지금부터 위에서 말한 가치=q*(a) 이고 , 이 가치는 「보상의 확률 기대값」 으로 정의되며, 「행동 a 를 취했을 때 조건」의 확률이다. 여기서 소문자 q*(a) 가치는, 「현재는 알지 못하지만 실제값」 이고 우리가 앞으로 할일은 추정값(Estimation) Q_t(a) 가 기대값 q*(a)와 가까워지게 만드는 일이다.
탐색과 활용(Exploration and Exploitation) :: Q_t(a) 를 추정하는 방법 == 행동 가치 방법 Action value Method
행동가치방법(Action-value Method) 은 2 가지로 쪼갤 수 있다.
1. 행동의 가치를 추정
2. 행동을 선택
1. 행동 가치 추정
우리가 만들 Q_t(a)는 어떤 방식으로 수학식을 세워야 할까?
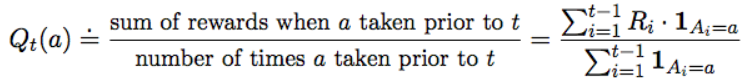
※ 여기서 조건서술어 '1'은 참이면 1, 거짓이면 0을 나타내는 '확률변수' 이다.
이 수식은 "내가 선택해서 받은 보상 / 선택한 횟수 " 를 의미한다. (왜냐면 레버를 당길지 말지 두가지 선택 밖에 없기 때문이다)
( 그리고 이 수식 자체가 문제를 수식화로 모델링 한 것이다. 이게 최선의 수식은 아니다 ! 앞으로 나올 수식들이 어떻게 전개되는 것인지 감을 잡기위해 가장 간단히 모델링 한것이다 !)
그리고 이제 샘플을 많이 취할수록 ( 위 식의 ∑ 에서 t→∞ ) , 수리통계학의 큰수의 법칙에 따라 Qt(a)는 q*(a)에 근사하게 된다.
단지 샘플을 많이 뽑았을 때 샘플 평균이 모집단의 평균이 된다는 것, 어떻게 보면 당연한 소리다
2. 행동선택
우리가 어떤 행동을 선택할지 고민하는 것으로, 다른 말로 하면 전략이 될 수 있다.
근데 위에서 제시한 Q_t(a) 함수가 누적합이기 때문에, 우리는 step t에 대해서 다음과 같이 가치를 update 할 것이다.

왜냐면, 매번 1~n 까지 다 더하는 계산을 하면 비효율적이기도 하고 컴퓨터의 메모리에는 한계가 있기 때문이다. 이 식을 잘 기억해두도록 하자.
그런데 이 공식은 Stationary Problem 에서만 적용된다 ( time이 변해도 Reward의 pdf가 변하지 않는 경우)
non-stationary problem 에서는 최근의 Reward에 대해 weight 를 주는 것이 타당하고 그 경우 다음과 같은 식을 사용한다.
( 아이돌 인기투표로 예를 들자면 , 2000년대에 동방신기의 누적 인기가 2천이고, 2010년대에 BTS가 급격하게 증가했는데 만약에 2천을 못넘었다고 가정할 때, 우리가 알고 싶은게 최신 트렌드의 아이돌 인기라면 최근의 이슈에 대해 가중치를 주는 것이 타당하다.)
Qn+1 = (1-a)^n Q1 + sum{ a(1-a)^n-i * Ri }
전략 1. Greedy:
(새로운 가능성이 불가능, 꼰대가 된다)
이 전략은 내가 알고 있는 지식만을 활용(Exploitation)한다.
이 전략에는 문제가 있다. 내가 모르는 지식이 내가 알고 있는 것 보다 좋다면 어떻게 할 것인가?
탐험(Exploration)이 충분히 이루어지지 않았다.
전략 2. e-Greedy:

전략1을 수정한 전략이다. 가뭄에 콩나듯이 Random을 탐험(Exploration)을 하는 e-greedy 방법이다.
이 방법의 장점은, t의 개수(시간)이 무한으로 커지면 큰수의 법칙에 따라 Qt(a)는 q*(a)로 수렴한다.
「1. 행동 가치 추정」 에서 하고자 했던 것과 일치한다.
(탐욕적 행동을 선택할 확률 = 1-e)
Initialize, for a=1 to k ; //k개의 선택지에 대해서
Q(a) <- 0 // 가치 (Average Reward)
N(a) <- 0 // step
infinite loop :
A <- (1-e)의 확률로 argmax Q(a) // greedy
<- e의 확률로 random action
R <- banddit(A) // A선택에 대한 reward를 계산하는 function
N(A)+=1 // next step
Q(A)<-Q(A) + alpha[ R - Q(A) ] // 가치 update
전략 3. Upper-Confidence-Bound (UCB):
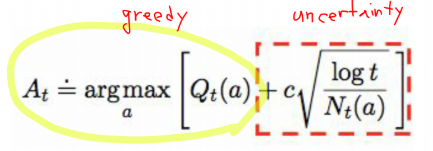
t= 시간 , N_t(a) = a가 선택된 횟수
최적이 될 가능성을 수치로 계산하여 전략2의 탐험을 시행한다.
앞부분은 greedy이고, 전략 2의 epsilon을 다른 방법으로 수식을 모델링하여 하나의 식으로 표현한 것이다.
이 식의 의미는 greedy 하게 선택하되, 선택이 안 된 후보 군들 중에 더 좋은 가능성이 있는 애가 있을 수 있으므로 선택될 기회를 주는 것이다. 후보를 오랫동안 선택하지 않으면 가중치가 높아지게 된다.
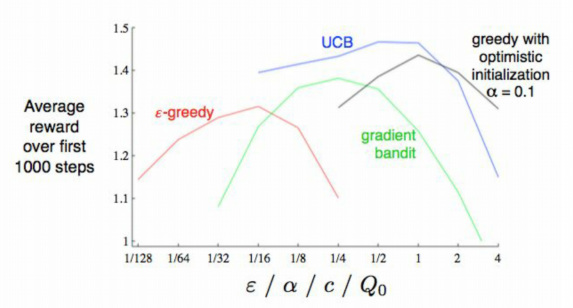
아래는 위에서 설명한 4가지 MAB Problem 의 Action Algorithm 을 비교한 결과이다.
이 결과 UCB가 가장 좋은 퍼포먼스를 보이고, 실제로는 e-greedy와 UCB를 가장 많이 사용하고 있다.
강화학습(RL)과 MAB 사이의 중간쯤에 있는 것으로 Contextual Bandit Problem이 있다.
지금까지는 행동(Action) 간의 연관성이 없었지만, 연관성이 생기는 경우이다.
Contextual Bandit은 RL의 policy학습 개념, MAB의 Reward 개념이 있다.
그리고 Contextual Bandit에 State Transition을 추가하면 RL이 된다. (State transition은 다음 상황에 영향을 준다)
Reference
멀티 암드 밴딧(Multi-Armed Bandits)
심플하고 직관적인 학습 알고리즘 | 강화학습의 정통 교과서라할 수 있는 Sutton 교수님의 Reinforcement Learning : An Introduction 책을 읽어보자. 챕터 1에서는 앞으로 다룰 내용에 대한 개요가 나오며, 챕터 2부터 본격적으로 기초 이론을 다루게 된다. 챕터 2의 제목이 바로 멀티 암드 밴딧(Multi-armed Bandits, 이하 MAB)이다. 사실,
brunch.co.kr
* Thompson Sampling 브런치 글 https://brunch.co.kr/@chris-song/66
톰슨 샘플링 for Bandits
밴딧 문제를 해결하는 또 하나의 baseline | 이번 포스팅에서는 톰슨 샘플링에 대해 소개해드리겠습니다. 멀티암드밴딧(MAB) 보다는 좀 더 어려운 확률이론이 나오니, 먼저 대학교 때 기말고사를 보
brunch.co.kr
T.B.D
Stochastic gradient ascent :
여러개의 행동 중 행동 a 를 선택할 확률 Pi_t(a) = soft max functin for action
그리고 이 pi를 누적한 값 : 선호도 H_t(a)
E[R_t] = sumof (pi_(x) * q*(x) ] = 선택할 확률 * 참값
이 기대값을 H로 나누면 (편미분) 하면 , 확률론적 경사도 stocastic grad가 됨.
MAB에서 탐험과 활용의 균형 방법 :: gittins index
baysian의 일종이다. 최선의 선택은 사후 확률인 tompson sampling으로 찾는다.
사후 확률 = 단서가 주어 졌을 때 확률 분포를 업데이트 함
gamma function = factorial function의 정의역을 복소수로 확장
gamma function의 ratio = 베타함수
베타분포 = 톰슨 샘플링 핵심 개념 ( 2개의 변수에 대한 분포 )
'AI > RL' 카테고리의 다른 글
| [단단한 강화학습] #1 강화학습 소개 (0) | 2020.05.07 |
|---|---|
| [스터디파이] 강화학습 단기집중 과정 Course 참여 (1) | 2020.05.07 |