2020. 8. 30. 20:19ㆍAI/DL
개념설명 & 과제를 진행할 같아요. 그리고 실전으로 가벼운 코딩 문제 여러 개 풀기?
[교재]
fastai/fastbook
Draft of the fastai book. Contribute to fastai/fastbook development by creating an account on GitHub.
github.com
| Chapter 1. Intro | 페이지 |
| 1. Deep Learning Is for Everyone | 3 |
| 2. How to Learn Deep Learning | 12 |
| 3. The Software: PyTorch, fastai, and Jupyter (And Why It Doesn’t Matter) | 12 |
| 4. Running Your First Notebook | 20 |
| 5. What Is Machine Learning? | 20 |
| 6. Limitations Inherent to ML | 26 |
| 7. How Our Image Recognizer Works | 26 |
| 8. What Our Image Recognizer Learned | 36 |
| 9. Image Recognizers Can Tackle Non-Image Tasks | 36 |
| 10. Deep Learning Is Not Just for Image Classification | 48 |
| 11. Validation Sets and Test Sets | 48 |
| 12. A Choose Your Own Adventure Moment | 54 |
0. Your Deep Learning Journey
- 딥러닝 이면의 핵심 개념을 소개한다.
- 기술적 배경이나 수학적 배경에서 오지 않아도 괜찮다.
1. Deep Learning Is for Everyone
[딥러닝에 대한 잘못된 이야기와 진실]
- 수학이 많이 필요하다 >> 고등학교 수학만으로 충분합니다
- 많은 데이터 >> 50개 미만에서도 유의미한 결과를 보았습니다.
- 비싼 컴퓨터 >> 무료로 충분히 얻을 수 있습니다.
[딥러닝]
- 신경망을 이용하여, 데이터를 추출하고 변환하는 컴퓨터 기법
- Layer는 오류를 최소화하고 정확성을 향상시키도록 훈련 됨
[딥러닝을 사용하는 분야]
- 자연어 처리(NLP): 질문 답변, 음성 인식, 문서 요약, 문서 분류, 문서 이름 찾기, 날짜 찾기, 개념 언급 기사 검색
- 컴퓨터 비전: 위성 및 드론 이미지 해석(예: 재해 복구용), 얼굴 인식, 이미지 캡션, 교통 표지판 읽기, 자동 차량 내 보행자 및 차량 위치 확인
- 약학: CT, MRI, X선 영상을 포함한 방사선 영상에서 이상 징후 발견, 병리학 슬라이드의 특징 개수, 초음파 측정 기능, 당뇨병성 망막병증 진단
- 생물학: 접이식 단백질, 단백질 분류, 종양-정상 염기서열 분석 및 임상적으로 실행 가능한 유전자 돌연변이 분류, 세포 분류, 단백질/단백질 상호작용 분석 등 많은 유전체학 과제
- 이미지 생성: 이미지 색조화, 이미지 해상도 향상, 이미지 노이즈 제거, 유명 아티스트 스타일로 이미지 변환
- 추천 시스템: 웹 검색, 제품 권장 사항, 홈 페이지 레이아웃
- 게임: 체스, 바둑, 대부분의 아타리 비디오 게임, 그리고 많은 실시간 전략 게임
- 로보틱스: 찾기가 어렵거나(예: 투명, 광택, 텍스처 부족) 픽업하기 어려운 객체 취급
- 기타 응용 프로그램: 재무 및 물류 예측, 텍스트 음성 변환 등...
주목할 것은, 적용분야는 달라도 딥러닝은 신경망에 기초하고 있다.
이에 대한 시야가 넓어지기 위해서는 역사에서 출발하는 것이 좋다.
Neural Networks: A Brief History
1943년 신경생리학자 Warren McCulloch와 논리학자 Walter Pitts가 팀을 이뤄 인공 뉴런의 수학적 모델을 개발했다.
그들은 paper "A Logical Calculus of the Ideas Immanent in Nervous Activity"에서 다음과 같이 선언했다.
"All-or-none" 특성 때문에, 명제논리로 처리할 수 있다.
뉴런의 수학적 모델은, add와 threshold를 사용하여 간단하게 modeling 할 수 있다.

그러나 다들 알다시피 XOR 같은 중요 수학 함수를 배울 수 없음이 보여짐으로써, 향후 20년동안 학계는 신경망을 포기했었다.
지난 50년간 Neural Network 에서 중요한 작업은 1986년 MIT Press에서 발표한 다량 병렬 분산 처리(Parallel Distribution Processing, PDP) 이다. (현대 인공신경망과 유사)
80-90년대 신경망 모델들은 이론적으로, 뉴런의 한 층만 더하면 어떤 수학적인 기능도 이러한 신경망과 근사하게 추정할 수 있을 만큼 충분했지만, 실제로 그러한 네트워크는 종종 너무 크고 너무 느려서 유용하지 못했다.
연구자들은 30년 전에 실용적으로 좋은 성능을 얻기 위해서는 훨씬 더 많은 뉴런 층을 사용해야 한다는 것을 보여주었지만, 이 원리가 더 널리 인정받고 적용되어 온 것은 지난 10년 동안이다.
신경 네트워크는 컴퓨터 하드웨어의 개선, 데이터 가용성 증가, 신경 네트워크를 더 빠르고 쉽게 훈련시킬 수 있는 알고리즘 트윗으로 인해 더 많은 계층의 사용과 결합한 덕분에 마침내 그들의 잠재력에 부응하고 있다.
2. How to Learn Deep Learning
- 야구를 가르치려면, 먼저 야구 경기에 데려가거나 야구를 플레이하게 하세요!
- 음악을 가르친다면, 먼저 음악을 듣거나 연주하도록 하세요!
- 딥러닝을 가르친다면, 먼저 모델을 만들고 더 나은 모델을 만들고자하는 동기를 갖게 하세요!
- 불행히도, 여기서 딥러닝에 관한 많은 교육 자원이 시작된다.
- 학습자들은 실제 작동 코드의 예를 전혀 제시하지 않고 헤시안 및 테일러의 손실 기능의 근사치 정의와 함께 따라야 한다
- 당신은 실제 경험을 통해서만 더 나아질 수 있다.
- 그 이론에 너무 많은 시간을 투자하려고 하는 것은 역효과를 만들 수 있다.
기억하라, 딥러닝에서 성공하기 위해 특별한 학력이 필요하지 않다.
지난 10년간 가장 영향력 있는 논문 중 하나인 "Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks" 같은 박사학위가 없는 사람들에 의한 연구와 산업에서 많은 중요한 발전이 이루어졌다.
"박사 학위는 꼭 필요하지 않습니다.
중요한 것은 AI에 대한 깊은 이해와 실제로 유용한 방식으로 NN을 구현하는 능력입니다.
고등학교를 졸업해도 상관 없습니다."
- Elon Musk
3. The Software: PyTorch, fastai, and Jupyter (And Why It Doesn’t Matter)
우리는 파이토치가 딥러닝을 위한 가장 유연하고 표현력이 풍부한 library라는 것을 발견했다.
PyTorch는 단순함과 속도, 두 가지를 모두 제공한다.
- fast.ai는 PyTorch 기반 higher-leverl functionality를 제공(이 책은 fastai v2 사용)
- 어떤 라이브러리를 사용하는가 자체는 크게 중요하지 않음
- 고수준 개념 설명에는 fastai를, 저수준 개념 설명에는 pytorch나 순수 python 사용 예정
- 어차피 몇년 있으면 또 새로운 게 나올 것
- 새로운 것들이 너무 빠르게 등장하고 있는 상황에서 정말 중요한 포인트는
밑바탕에 있는 테크닉과 어떻게 그것들을 실전에 적용하며,
새로운 툴과 테크닉들이 발표될 때,
얼마나 빠르게 전문성을 키울 수 있는가에 초점을 맞추는 것 - fastai의 사용법과 내부 구현까지를 모두 이해하는 것이 목표
4. Running Your First Model
- 말했던 것처럼, 어떻게 작동하는지 설명하기 전에 동작하는 것을 보여줄 것이다.
- Top-down 방식으로 진행
Colab을 사용하자
Google Colaboratory
colab.research.google.com
#id first_training
#caption Results from the first training
# CLICK ME
from fastai.vision.all import *
path = untar_data(URLs.PETS)/'images'
def is_cat(x): return x[0].isupper()
dls = ImageDataLoaders.from_name_func(
path, get_image_files(path), valid_pct=0.2, seed=42,
label_func=is_cat, item_tfms=Resize(224))
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(1)위 코드는 다음 동작을 수행한다.
1. Oxford-IIIT Pet Dataset에서 7,349장의 고양이/강아지 사진 데이터를 다운로드 후 압축해제
2. pretrained model을 다운로드( resnet34 )
3. 2.에서 받은 pretrained model에 대해 fine tuning 진행
이 모델이 괜찮은지 어떻게 알 수 있을까?
표의 마지막 열에서 잘못 식별된 영상의 비율인 오류율을 볼 수 있다.
마지막으로 이 모델이 실제로 작동하는지 확인해 봅시다. 가서 개나 고양이의 사진을 가져오세요.
#hide_output
uploader = widgets.FileUpload()
uploader#hide
# For the book, we can't actually click an upload button, so we fake it
uploader = SimpleNamespace(data = ['images/chapter1_cat_example.jpg'])
img = PILImage.create(uploader.data[0])
is_cat,_,probs = learn.predict(img)
print(f"Is this a cat?: {is_cat}.")
print(f"Probability it's a cat: {probs[1].item():.6f}")
Is this a cat?: True.
Probability it's a cat: 0.999986Congratulations on your first classifier!
5. What Is Machine Learning?
- 딥러닝 모델은 신경망을 사용한다.
- 신경망은 1950년대부터 시작되었다.
- 딥러닝은 ML의 현대적인 영역이다.
- 이 Section은 ML이 무엇인지 설명한다.
- 주요 개념들을 살펴본다.
- ML은 그냥 프로그래밍처럼, 컴퓨터가 작업을 완료하게 만드는 방법이다.
- Programming을 할 때, 우리는 Program을 작성한다.
#hide_input
#caption A traditional program
#id basic_program
#alt Pipeline inputs, program, results
gv('''program[shape=box3d width=1 height=0.7]
inputs->program->results''')- 그런데, Program을 작성하는 방법은, Object를 Detection하는데는 적합하지 않다.
- Recognition 하는 과정은 우리가 의식하지 않는 순간에 뇌에서 일어나기 때문에,
이를 매순간의 flow로 Program을 작성하는 것은 쉽지 않다.
- 그래서 방법을 바꿨다.
- 1962년, IBM의 Arthur Samuel, "Artificial Intelligence : A Frontier of Automation"
- 해결에 필요한 단계를 작성하기 보다는
- 풀어야 할 문제의 예를 보여주고, 해결 방법을 컴퓨터가 작성하도록 바꿧다.
- 4가지 중요개념
| Weight Assignment | Actual Performance | Automatic Means | Mechanism |
| : 단순한 변수 | : 가중치를 준 결과 | : 결과를 자동으로 시험하는 수단 | : 가중치를 수정해서 결과를 개선하는 방법 |
4가지 중요개념을 하나씩 알아본다
Weight : 변수에 불과하다.
#hide_input
#caption A program using weight assignment
#id weight_assignment
gv('''model[shape=box3d width=1 height=0.7]
inputs->model->results; weights->model''')[주요 변경점]
- Box 이름 : Program → Model :: 모델은 프로그램의 특별한 한 형태임을 반영
- weight는 요새 parameter라고도 불린다.
- 용어는 시대에 따라 다르게 불리기도 함.
- 중요한 것은 개념은 변하지 않는다는 것
Automatic Means :
- 두 model이 대결하도록 설정하고, 이기는 모델을 보면 성능을 자동으로 테스트 할 수 있다.
Mechanism :
- 이긴 모델과 진 모델의 weight를 열어보고, 이긴 모델의 weight 쪽으로 weight를 변경한다.
#hide_input
#caption Training a machine learning model
#id training_loop
#alt The basic training loop
gv('''ordering=in
model[shape=box3d width=1 height=0.7]
inputs->model->results; weights->model; results->performance
performance->weights[constraint=false label=update]''')모델이 훈련되어서 최종으로 도달하면, 더 이상 weight가 변화하지 않을 거에요.
그러면 우리가 처음 생각했던 프로그램과 같은 형태로 나올 거에요
What Is a Neural Network
- 전략을 선택 하는 체커 프로그램과 같은 곳에서 가중치가 어떻게 선택 될지 상상하는 것은 어렵지 않다.
- 그러나 Recognition과 같이 의식하기 전에 일어나는, 이미지 인식/텍스트 이해 같은 곳에서 어떻게 모델이 보일지는 분명하지 않다.
- 하지만, Weight를 변화시킴으로써 Recognition과 같은 문제를 풀 수 있는 것이 가능하다.
- 그만큼 신경망이 유연하고, 또 한편으로는 그러한 문제를 해결하기에 신경망이 적절하다는 것을 의미한다.
- 신경망은 강력하다.
- 혹시 "메커니즘"이 완전히 새롭지는 않을까? 그런 일반적인 방법도 존재한다.
- 이것을 SGD 라고 부른다.
- SGD가 어떻게 작용하는지 알아본다.
A Bit of Deep Learning Jargon
| Architecture | Weight | Predictions | results | measure of performance |
| model의 기능적 형태 | Parameter | 독립변수의 결과 | predictions | loss |
- loss는 예측값과 참값 둘다에 영향을 받는다.
#hide_input
#caption Detailed training loop
#id detailed_loop
gv('''ordering=in
model[shape=box3d width=1 height=0.7 label=architecture]
inputs->model->predictions; parameters->model; labels->loss; predictions->loss
loss->parameters[constraint=false label=update]''')6. Limitations Inherent to ML
이 그림에서 딥러닝 모델 훈련의 기본적인 것들을 볼 수 있다.
- input data가 없으면 만들어 질 수 없다.
- 모델에서 나오는 것은 오직 Prediction이다. action이 아니다.
- input data만 가지고 만들어지지는 않는다. label도 필요하다
일반적으로 조직에서 Data가 충분하지 않다는 것은, Label이 붙여진 Data가 충분하지 않다는 것을 의미한다.
이 책에서는 Labeling 접근법에 대해서 많이 논의 할 것이다. 그것은 중요한 사안이기 때문이다.
이런 류의 Model은 Prediction만 할 수 있기 때문에, 조직 목표와 차이가 많이 날 수 있다.
예를 들어, 이번에 들어 본적 없는 제품에 대해서는 예측을 못할 수 있다.
모델이 환경과 상호작용(피드백) 하는 방법을 고려하면 통찰력을 얻을 수 있다.
- Env를 기반으로 Predictive policing model을 생성한다.
- Env가 변화하면 이를 model에 반영한다.
이것을 Positive Feedback loop라고 하며, input이 Biasing 될 수 록 Output도 더 Biasing 된다.
극단적인 예로, 추천시스템에서 특정콘텐츠에 편중되어 추천될 수 있다.
7. How Our Image Recognizer Works
1. library를 가져온다
from fastai.vision.all import *2. Dataset을 가져오고, 가져온 경로를 반환한다.
path = untar_data(URLs.PETS)/'images'3. Data 작성자가 제공한 파일이름 규칙에 따라 label을 지정한다
def is_cat(x): return x[0].isupper()4. ImageDataLoaders.from_name_func () 함수
각 매개변수에 대해 설명합니다.
dls = ImageDataLoaders.from_name_func(path, get_image_files(path), valid_pct=0.2, seed=42, label_func=is_cat, item_tfms=Resize(224))
- ImageDataLoaders : 이미지 데이터를 불러오겠다는 클래스
- label_func : 데이터 집합의 라벨이 지정된 곳
- Transform :
- item_tfms : 개별 item에 대하여 transform. 위 경우는 224-px로 resize
- batch_tfms : GPU를 사용하여 한번에 일괄적으로 적용 (속도가 빠름)
왜 224 Pixel 인가요?
예전에 pretrained 된 model 들은 무조건 이 크기였다 (-_-) ...
그래서 옛날 모델에 태울 때는 이 사이즈를 맞춰야한다.
- 분류(Classification) : 범주형 자료에 대하여 Prediction
- 회귀(Regression) : 이산형 자료에 대하여 Prediction
- [label_func]
- 펫 데이터셋에는 37종의 개/고양이의 사진이 7,390점이 담겨있다.
def is_cat(x): return x[0].isupper()- is_cat() 함수에 의해, 이미지의 파일이름이 UpperCase인지 LowerCase인지로 고양이/개 를 분류한다.
- [valid_pct=0.2]
- 이를 통해 fastai는 모델 훈련에 사용되지 않도록 데이터의 20%를 유지합니다.
- 이 데이터를 검증집합 이라고 하며, 나머지 80%를 교육 집합이라고 합니다.
- 기본적으로 20%는 무작위로 선정되며, 매개변수 seed 값을 통해 반복적 구현시 동일한 유효성 검사 셋을 얻도록 할 수 있습니다.
- 검증집합이 바뀐다고 모델이 바뀌지 않습니다 (맞나?)
- 모델 훈련시, 특정 데이터가 암기 되었을 수도 있습니다.
훈련을 오래 할 수록 정확도는 좋아지겠지만, 암기를 하기 시작하면서
변화에 유연하게 대처하지 못합니다. 이를 과적합이라고 합니다.
과적합(오버피팅)
- Training시 정확도를 높이는 것은 쉽지만, Prediction을 잘하는 모델은 어렵습니다.
- 여러분은 이 책에서 오버피팅 하지 않는 방법을 배울 것 입니다.
- 그렇게 할 필요가 없음에도 적합한 회피 기법을 사용하기도 하는데, 이는 본래보다 덜 정확할 수 있는 모델로 귀결 됩니다.
정확도
- 정확도는 Valid data set에서만 측정해야 합니다.
- train은 시간이 지날수록 정확도가 올라가기 때문입니다.
5. CNN을 만들고, metric을 명시합니다.
learn = cnn_learner(dls, resnet34, metrics=error_rate)- 왜 CNN 인가요? 비전 모델을 만들 때는 CNN이 최첨단 접근 법입니다.
- 이 구조는 인간의 시각 시스템의 영감을 받아 작동합니다.
- 여기서는 ResNet 34를 씁니다. Layer가 깊으면 오버피팅 하기 쉽니다.
(Valid의 정확성이 떨어지기 때문)
[metric]
- Valid set을 이용하여, Prediction의 품질을 측정
- 매 epoch 마다 출력된다.
- 여기서는 error_rate (1-accuracy) 를 지표로 삼았다.
8. What Our Image Recognizer Learned
여기에는 매우 잘 작동하는 이미지 인식기가 있습니다. 하지만 이미지 인식기가 실제로 무엇을 하고 있는지 알 수 없습니다 (블랙박스 모델).
이와 관련되어서 2013년 박사과정 학생 Matt Zeiler가 모델의 각 계층에서 학습된 신경망 가중치를 시각화하는 방법을 보여주는 논문 "Visualizing and Understanding Convolutional Networks"를 발표 했습니다.
이 그림은 약간의 설명이 필요합니다.
- 각 레이어에 대해 밝은 회색 배경을 가진 영상 파트는 재구성된 가중치 그림을 보여주고,
- 하단의 큰 섹션은 각 가중치 세트와 가장 강하게 일치하는 훈련 이미지의 부분을 보여줍니다.
레이어 1의 경우, 모델이 다양한 그레이디언트뿐만 아니라 대각선, 수평 및 수직 모서리를 나타내는 가중치를 발견했다는 것을 알 수 있습니다. 각 계층에 대해 일부 기능만 표시됩니다. 실제로 모든 계층에는 수천 개의 기능이 있습니다. 이것들은 모델이 컴퓨터 비전을 위해 배운 기본적인 구성 요소들입니다.
레이어 2의 경우 모델에 의해 발견된 각 형상에 대한 가중치 재구성의 9가지 예가 있습니다.
- 모델이 모서리, 반복 선, 원 및 기타 간단한 패턴을 찾는 기능 디텍터를 만드는 방법을 학습했음을 알 수 있습니다.
이러한 구성 요소는
- 첫 번째 계층에서 개발된 기본 구성 요소로 이루어집니다.
각 사진의 오른쪽에는 실제 이미지의 작은 패치가 표시되어 있으며, 이 패치는 이러한 기능이 가장 근접하게 일치합니다.
보다 일반적으로, 우리는 이러한 사전 훈련된 모델을 많은 다양한 작업에 전문화할 수 있습니다. 몇 가지 예를 들어 보겠습니다.
9. Image Recognizers Can Tackle Non-Image Tasks
이미지 인식기는 이름에서 알 수 있듯이 이미지만 인식할 수 있습니다.
하지만 많은 것들이 이미지로 표현될 수 있습니다.
이것은 이미지 인식자가 많은 작업을 완료하는 법을 배울 수 있다는 것을 의미합니다.
예를 들어, 사운드는 스펙트럼 프로그램으로 변환될 수 있으며, 이는 오디오 파일에서 각 주파수의 양을 보여주는 차트입니다.
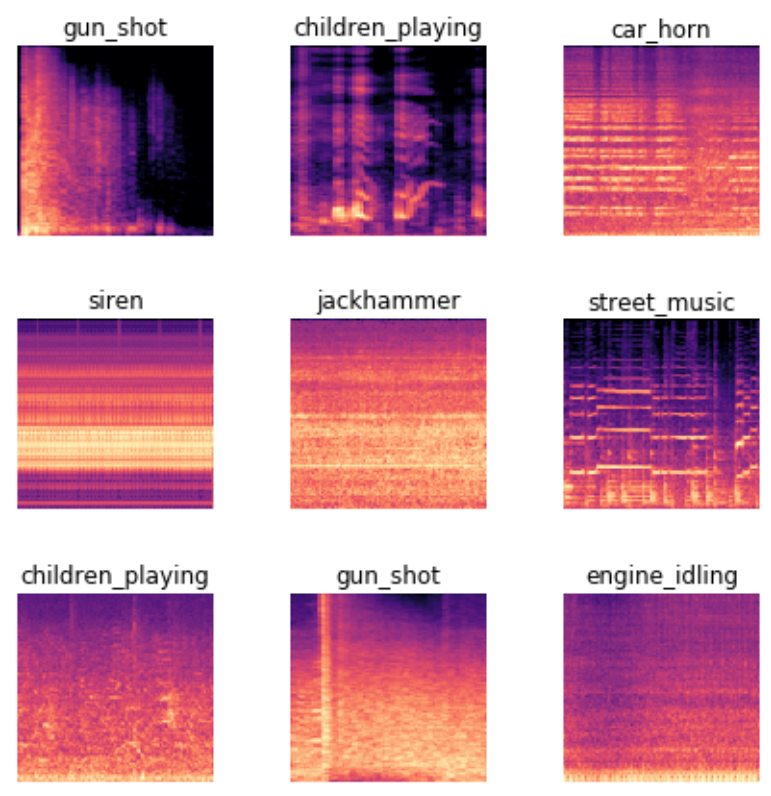
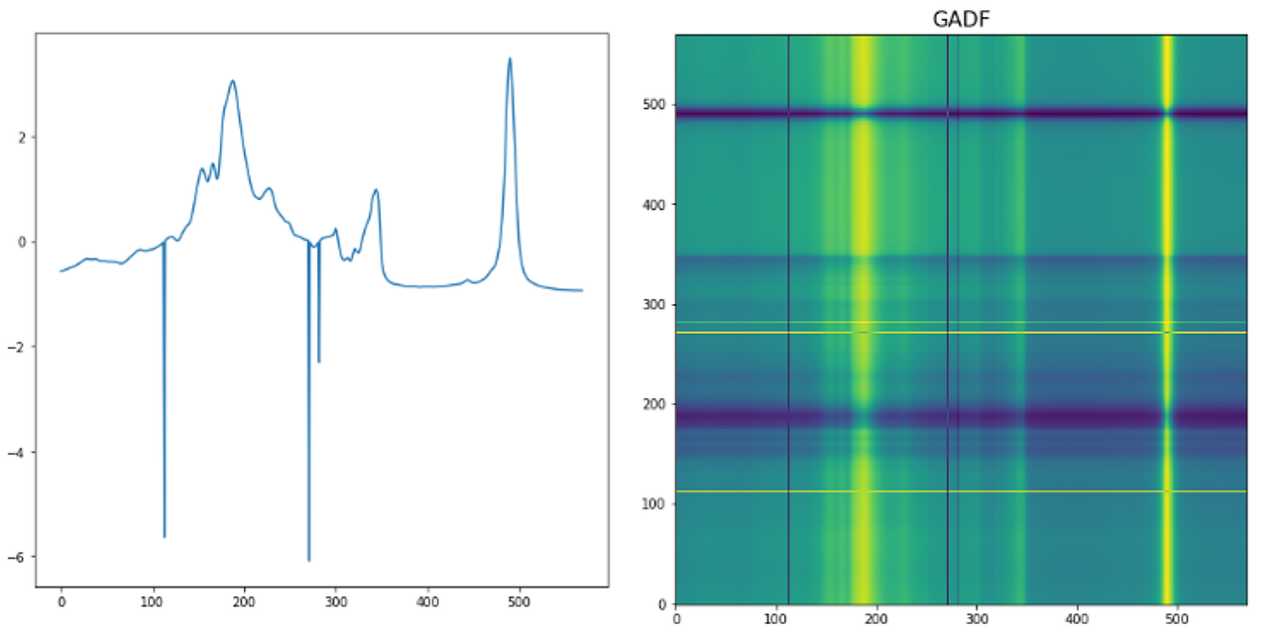
또 다른 흥미로운 것은 사용자의 마우스 움직임과 마우스 클릭의 데이터 세트를 사용하여 부정 행위 탐지 작업을 수행한 것 입니다. 마우스 포인터의 위치, 속도 및 가속도가 컬러 선을 사용하여 표시되고 클릭이 작은 컬러 원을 사용하여 표시되는 이미지를 그림으로 변환했습니다
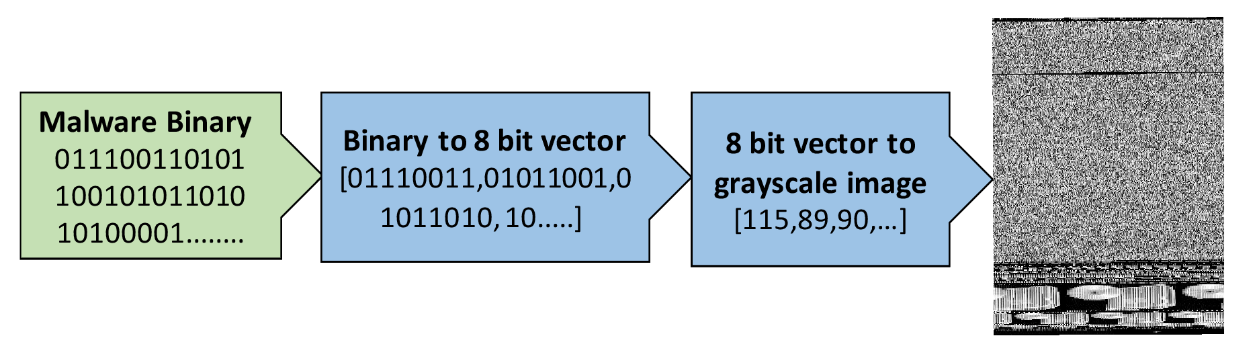
또 다른 예는, Mahmoud Kalash 등이 쓴 "Deep Convolutional Neural Networks를 이용한 Malware Classification"이라는 논문에서 나왔는데, "악성코드 이진 파일이 8비트 시퀀스로 분할된 후 동일한 소수 값으로 변환됩니다. 이 10진 벡터는 재구성되고 맬웨어 샘플을 나타내는 그레이 스케일 이미지가 생성됩니다.

잠시 시간을 내어 이러한 정의를 검토하고 다음 요약을 읽어 보십시오.
설명을 따를 수 있다면 앞으로의 논의를 이해할 수 있는 충분한 준비가 되어 있습니다.
기계 학습은 우리가 프로그램을 완전히 스스로 쓰는 것이 아니라 자료로부터 배우는 것을 통해 프로그램을 정의하는 학문입니다. 딥 러닝은 여러 계층이 있는 신경망을 사용하는 머신 러닝의 전문 분야입니다. 이미지 분류가 대표적인 예입니다(이미지 인식이라고도 함).
먼저 레이블링된 데이터부터 시작합니다. 즉, 각 이미지에 레이블을 할당하여 해당 데이터를 나타내는 이미지 집합입니다. 우리의 목표는 모델이라고 불리는 프로그램을 만드는 것입니다. 새로운 이미지가 주어지면, 새로운 이미지가 무엇을 나타내는지에 대한 정확한 예측을 할 것입니다.
모든 모델은 이러한 종류의 모델이 내부적으로 어떻게 작동하는지에 대한 일반적인 템플릿인 아키텍처 선택으로 시작합니다. 모델을 교육(또는 적합)하는 프로세스는 일반적인 아키텍처를 특정 유형의 데이터에 적합한 모델로 전문화하는 일련의 매개 변수 값(또는 가중치)을 찾는 프로세스입니다. 모형이 단일 예측에서 얼마나 잘 수행하는지 정의하려면 예측의 점수를 좋은 점수로 매기는 손실 함수를 정의해야 합니다.
교육 프로세스를 보다 빠르게 진행하기 위해 사전 교육을 받은 모델, 즉 이미 다른 사람의 데이터에 대해 교육을 받은 모델부터 시작할 수 있습니다. 그런 다음 미세 조정이라고 하는 프로세스를 통해 데이터를 좀 더 학습함으로써 데이터에 적응시킬 수 있습니다.
모델을 교육할 때 중요한 관심사는 모델이 일반화할 수 있도록 하는 것입니다.
즉, 모델이 접하게 될 새로운 항목에도 적용되는 데이터로부터 일반적인 교훈을 학습하여 해당 항목에 대해 좋은 예측을 할 수 있도록 하는 것입니다. 위험성은 우리가 모델을 잘못 훈련시키면, 일반적인 교훈을 배우는 대신, 이미 본 것을 효과적으로 암기하게 되고, 그러면 새로운 이미지에 대한 예측이 잘못될 것입니다. 이러한 고장을 과적합이라고 합니다. 이를 방지하기 위해 항상 데이터를 교육 세트와 검증 세트 두 부분으로 나눕니다. 우리는 교육 세트만 보여주면서 모델을 교육한 다음 검증 세트의 항목에서 모델의 성능이 얼마나 좋은지 확인함으로써 모델의 성능을 평가합니다. 이러한 방식으로 모델이 교육 세트에서 학습하는 교훈이 검증 세트로 일반화하는 교훈인지 확인합니다.
10. Deep Learning Is Not Just for Image Classification
이미지 분류에 대한 딥 러닝의 효과성은 최근 몇 년 동안 널리 논의되어 왔으며, CT 스캔에서 악성 종양을 인식하는 것과 같은 복잡한 작업에서 초인적인 결과를 보여주기도 했습니다. 하지만 여기 보여드릴 것처럼 이것보다 훨씬 더 많은 것을 할 수 있습니다.
예를 들어, 자율 주행 차량에 매우 중요한 것에 대해 이야기해 보겠습니다. 그림에서 물체를 위치시키는 것입니다. 만약 자율주행 자동차가 보행자가 어디에 있는지 모른다면, 어떻게 보행자를 피할 수 있을지 모릅니다! 이미지에서 모든 개별 픽셀의 콘텐츠를 인식할 수 있는 모델을 만드는 것을 분할이라고 합니다.
지난 몇 년 동안 딥 러닝이 극적으로 개선된 또 다른 분야는 자연어 처리(NLP)입니다. 이제 컴퓨터는 텍스트를 생성하고, 한 언어에서 다른 언어로 자동 번역하고, 주석을 분석하고, 문장의 단어를 레이블링하는 등의 작업을 수행할 수 있습니다.
이 섹션에는 이미 많은 모델이 나와 있으며, 각 모델은 다른 작업을 수행하기 위해 서로 다른 데이터 집합을 사용하여 교육되었습니다. 기계 학습과 딥 러닝에서는 데이터 없이는 아무것도 할 수 없습니다. 따라서 모델을 교육하기 위해 데이터셋을 만드는 사람들은 (때로는 인정받지 못하는) 영웅입니다.
가장 유용하고 중요한 데이터 세트 중 일부는 중요한 학술 기준이 되는 데이터 세트입니다. 즉, 연구자가 광범위하게 연구하여 알고리즘 변화를 비교하는 데 사용되는 데이터 세트입니다. 이들 중 일부는 MNIST, CIFAR-10 및 ImageNet과 같이 (적어도 모델을 교육하는 가구 중!) 호칭이 됩니다.
이 책에 사용된 데이터셋은 사용자가 접할 수 있는 데이터의 종류에 대한 훌륭한 예를 제공하기 때문에 선택되었으며, 학술 문헌에는 이러한 데이터셋을 사용한 모델 결과의 많은 예가 나와 있으며, 이를 통해 작업을 비교할 수 있습니다.
이 책에 사용된 대부분의 데이터셋은 작성자에게 많은 작업이 필요했습니다. 예를 들어, 책의 뒷부분에서 불어와 영어를 번역할 수 있는 모델을 만드는 방법을 보여드리겠습니다. 이에 대한 핵심 입력은 2009년 펜실베이니아 대학의 Chris Calison-Burch 교수가 작성한 프랑스어/영어 병렬 텍스트 말뭉치입니다. 이 데이터 세트에는 프랑스어 및 영어로 된 2천만 개 이상의 문장 쌍이 포함되어 있습니다. 그는 수백만 개의 캐나다 웹 페이지(다언어)를 탐색한 다음 간단한 경험적 접근 방식을 사용하여 동일한 콘텐츠를 가리키는 URL을 영어로 변환하는 방식으로 데이터 세트를 만들었습니다.
이 책 전체에서 데이터 세트를 살펴보면서 데이터셋의 출처는 무엇이고 데이터셋은 어떻게 수정되었을지 생각해 보십시오. 그렇다면 자신의 프로젝트를 위해 어떤 종류의 흥미로운 데이터셋을 만들 수 있는지 생각해 보십시오. (곧 자신만의 이미지 데이터 세트를 만드는 과정까지 단계별로 안내해 드립니다.)
fast.ai은 빠른 프로토타이핑과 실험을 지원하고 배우기 쉬운 인기 데이터 세트의 축소 버전을 만드는 데 많은 시간을 투자했습니다. 이 책에서 우리는 종종 컷다운 버전 중 하나를 사용하는 것으로 시작해서 나중에 풀사이즈 버전으로 확장될 것입니다(이 챕터에서처럼!). 실제로 세계 최고의 실무자들이 모델링을 수행하는 방식은 다음과 같습니다. 대부분의 실험과 프로토타이핑은 데이터의 부분 집합을 사용하여 수행하며, 해야 할 일을 잘 이해할 때만 전체 데이터 집합을 사용합니다.
11. Validation Sets and Test Sets
앞서 살펴본 바와 같이, 모델의 목표는 데이터에 대한 예측을 하는 것입니다.
하지만 모델 훈련 과정은 근본적으로 멍청합니다. 모든 데이터를 사용하여 모델을 학습한 다음 동일한 데이터를 사용하여 모델을 평가하면, 모델이 아직 보지 못한 데이터에 대해 얼마나 우수한 성능을 발휘할 수 있는지 알 수 없을 것입니다. 모델을 교육하는 데 도움이 되는 매우 귀중한 정보가 없다면, 해당 데이터가 예측에는 적합하지만 새로운 데이터에 대해서는 성능이 저하될 가능성이 매우 높습니다.
이를 피하기 위해 첫 번째 단계는 데이터 세트를 교육 세트(모델이 교육에서 보는 것)와 개발 세트(평가용으로만 사용됨)의 두 가지 세트로 나누는 것이었습니다. 이를 통해 모델이 새로운 데이터인 검증 데이터로 일반화하는 교육 데이터에서 교훈을 얻는다는 것을 테스트할 수 있습니다.
이 상황을 이해하는 한 가지 방법은, 어떤 의미에서는, 우리의 모델이 "속임"을 통해 좋은 결과를 얻기를 원하지 않는다는 것입니다. 데이터 항목에 대해 정확한 예측을 한다면, 이는 해당 항목의 특성을 학습했기 때문이지, 특정 항목을 실제로 보고 모델이 형성되었기 때문은 아닙니다.
검증 데이터를 분리한다는 것은 우리의 모델이 훈련에서 결코 그것을 보지 못하기 때문에 그것에 의해 완전히 오염되지 않고 어떠한 방법으로도 부정행위를 하지 않는다는 것을 의미합니다. 그렇죠?
사실 꼭 그렇지는 않습니다. 상황이 더 미묘합니다. 왜냐하면 현실적인 시나리오에서는 무게 매개 변수를 한 번만 훈련시켜도 모형을 만드는 경우가 거의 없기 때문입니다. 대신, 우리는 네트워크 아키텍처, 학습률, 데이터 확대 전략 및 다음 장에서 논의할 다른 요소들에 관한 다양한 모델링 선택을 통해 모델의 많은 버전을 탐구할 가능성이 높습니다.
이러한 선택 중 대부분은 하이퍼 파라미터 선택 사항으로 설명할 수 있습니다.
이 단어는 가중치 모수의 의미를 결정하는 상위 수준의 선택 항목이므로 모수에 대한 매개 변수임을 나타냅니다.
문제는 일반적인 훈련 과정이 무게 매개변수에 대한 값을 학습할 때 훈련 데이터에 대한 예측만 보는 것이기는 하지만, 우리와 같은 것은 아니라는 것입니다. 우리는 모델 제작자로서 새로운 하이퍼 파라미터 값을 탐색하기로 결정할 때 검증 데이터에 대한 예측을 보고 모델을 평가하고 있습니다! 따라서 모델의 후속 버전은 검증 데이터를 보고 간접적으로 형성됩니다. 자동 훈련 과정이 훈련 데이터를 과도하게 적합시킬 위험이 있는 것처럼, 우리는 인간의 시행착오와 탐사를 통해 검증 데이터를 과도하게 적합시킬 위험에 처해 있습니다.
이 문제에 대한 해결책은 훨씬 더 높은 예약 데이터인 테스트 세트를 또 다른 수준으로 도입하는 것입니다. 교육 프로세스의 검증 데이터를 보류하는 것과 마찬가지로, 테스트 세트 데이터도 우리 자신으로부터 보류해야 합니다. 모델을 개선하는 데 사용할 수 없습니다. 우리의 노력이 끝날 때에만 모델을 평가할 수 있습니다. 실제로, 우리는 교육 및 모델링 프로세스로부터 데이터를 얼마나 완벽하게 숨기기를 원하는지에 따라 데이터 절단 계층을 정의합니다. 교육 데이터는 완전히 노출되고 검증 데이터는 덜 노출되며 테스트 데이터는 완전히 숨겨집니다. 이 계층은 후방 전파를 이용한 자동 교육 프로세스, 교육 세션 간에 서로 다른 하이퍼 파라미터를 시도하는 보다 수동적인 프로세스, 최종 결과 평가 등 다양한 종류의 모델링 및 평가 프로세스와 유사합니다.
검정 및 검증 세트에는 정확성을 제대로 추정할 수 있는 충분한 데이터가 있어야 합니다. 예를 들어, 고양이 탐지기를 만드는 경우 일반적으로 적어도 30마리의 고양이가 검증 세트에 포함되기를 원할 수 있습니다. 즉, 수천 개의 항목이 포함된 데이터 집합이 있는 경우 기본 20% 유효성 검사 세트 크기를 사용하는 것이 필요한 것보다 많을 수 있습니다. 반면, 데이터가 많은 경우 검증을 위해 데이터 중 일부를 사용하는 것에는 단점이 없을 수 있습니다.
두 가지 수준의 "예약된 데이터" 즉, 검증 세트와 테스트 세트(가상적으로 자신으로부터 숨기고 있는 데이터를 나타내는 한 수준의 데이터)가 있는 것은 다소 극단적으로 보일 수 있습니다. 하지만 그것이 종종 필요한 이유는 모델들이 좋은 예측을 하는 가장 간단한 방법(기억력)으로 끌리는 경향이 있고, 우리 인간은 우리의 모델이 얼마나 잘 수행되고 있는지에 대해 스스로를 속이는 쪽으로 끌리는 경향이 있기 때문입니다. 시험 세트의 규율은 우리가 지적으로 정직하도록 돕습니다. 그렇다고 해서 항상 별도의 테스트 세트가 필요한 것은 아닙니다. 데이터가 매우 적은 경우에는 검증 세트만 있으면 됩니다. 하지만 일반적으로 가능하면 테스트 세트를 사용하는 것이 가장 좋습니다.
귀하를 대신하여 모델링 작업을 수행하기 위해 타사를 고용하려는 경우 이와 같은 규정이 매우 중요할 수 있습니다. 제3자가 사용자의 요구 사항을 정확하게 이해하지 못하거나 인센티브를 통해 고객의 요구 사항을 오해할 수 있습니다. 우수한 테스트 세트는 이러한 위험을 크게 완화할 수 있으며, 테스트 세트의 작업으로 실제 문제가 해결되었는지 여부를 평가할 수 있습니다.
즉, 조직의 선임 의사 결정권자(또는 선임 의사 결정권자에게 조언)인 경우 가장 중요한 이점은 다음과 같습니다. 즉, 테스트 및 검증 세트가 무엇인지, 그리고 검증 세트가 왜 중요한지 정확히 이해한다면, 조직이 결정할 때 경험했던 가장 큰 단일 장애 원인을 피할 수 있습니다. AI를 이용하기 위해서요 예를 들어 외부 공급업체나 서비스를 도입하려는 경우 공급업체에서 볼 수 없는 일부 테스트 데이터를 보류해야 합니다. 그런 다음 실제 사용자에게 중요한 사항을 기준으로 선택한 메트릭을 사용하여 테스트 데이터에서 해당 모델을 확인하고 적절한 성능 수준을 결정합니다. 간단한 기준을 직접 사용해 보는 것도 좋습니다. 그래서 정말 단순한 모델이 무엇을 성취할 수 있는지 알 수 있습니다. 종종 여러분의 단순한 모델이 외부 "전문가"가 만든 모델과 같은 성능을 발휘한다는 것이 밝혀지곤 합니다!
Use Judgment in Defining Test Sets
검증 세트(및 테스트 세트)를 잘 정의하려면 원본 데이터 세트의 일부를 랜덤하게 캡처하는 것 이상의 작업을 수행해야 할 경우가 있습니다. 검증 및 테스트 세트의 주요 속성은 미래에 보게 될 새로운 데이터를 대표해야 한다는 것입니다. 이것은 불가능한 주문처럼 들릴 수 있습니다! 정의상 이 데이터는 아직 보지 못했습니다. 하지만 여러분은 여전히 몇 가지를 알고 있습니다.
몇 가지 사례를 살펴보는 것이 유익합니다. 이러한 많은 예는 Kaggle 플랫폼의 예측 모델링 경쟁에서 나온 것입니다. 이는 실제로 볼 수 있는 문제와 방법을 잘 나타낸 것입니다.
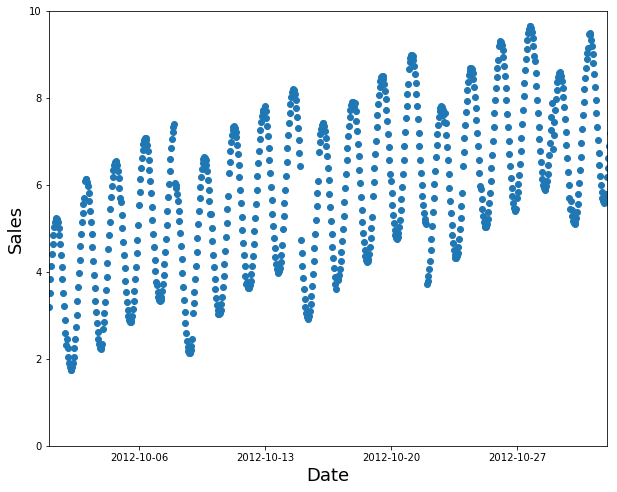
시계열 데이터를 보고 있는 경우가 한 가지 있을 수 있습니다. 시계열의 경우 데이터의 랜덤 부분 집합을 선택하는 것은 너무 쉬우며(예측하려는 날짜 이전과 이후의 데이터를 모두 볼 수 있음) 대부분의 비즈니스 사용 사례(이력 데이터를 사용하여 미래에 사용할 모델을 구축하는 경우)를 나타내는 것은 아닙니다. 데이터에 날짜가 포함되어 있고 향후 사용할 모델을 작성하는 경우, 최근 날짜(예: 사용 가능한 데이터의 최근 2주 또는 마지막 달)가 있는 연속 섹션을 유효성 검사 세트로 선택하려고 합니다.
12. A Choose Your Own Adventure Moment
오류 식별 및 수정, 실제 작동하는 웹 응용 프로그램 만들기, 모델이 조직이나 사회에 예기치 않은 손상을 초래하지 않도록 하는 방법 등 딥 러닝 모델을 실제로 사용하는 방법에 대해 자세히 알아보려면 다음 두 장을 계속 읽어 보십시오. 심층 학습이 어떻게 작동하는지에 대한 기초를 배우기 시작하려면 다음 단계로 넘어가십시오.
이 책의 더 발전하기 위해서는 이 모든 장을 읽어야 하지만, 그것들을 읽는 순서는 전적으로 당신에게 달려 있습니다. 그들은 서로에게 의지하지 않습니다. 다음 단계로 넘어가시면 됩니다.
'AI > DL' 카테고리의 다른 글
| [Fast.Ai] FaceBook Fast.Ai Kr Study #OT (0) | 2020.08.18 |
|---|---|
| [논문읽기] How Does Batch Normalization Help Optimization? (0) | 2020.07.21 |