2020. 7. 21. 23:35ㆍAI/DL
How Does Batch Normalization Help Optimization?
구성
2. Batch normalization and internal covariate shift
** 2.1 Does BatchNorm’s performance stem from controlling internal covariate shift?**
2.2 Is BatchNorm reducing internal covariate shift?
3.1 The smoothing effect of BatchNorm
3.2 Exploration of the optimization landscape
3.3 Is BatchNorm the best (only?) way to smoothen the landscape?
0. Abstract
BatchNormalization을 통해 DNN 을 더욱 빠르고 안정적으로 훈련시킬 수 있다.
그럼에도, Batch Norm의 효과에 대한 정확한 이유는 알려져 있지 않다.
일반적으로, " Internal Covariate Shift " 를 줄이기 위해 Training 중 "입력 분포의 변화"를 제어 하는 데서 비롯된다고 생각한다.
본 연구에서는, 입력의 분포적 안정성과 Batch Norm의 성공과는 관계가 없음을 증명한다.
대신 Batch Norm이 Training에 미치는 근본적인 영향을 파악한다.
근본적인 영향은, 최적화 환경을 더 부드럽게(smoother) 만든다는 것이다.
이 부드러움은 예측적이고 안정적은 gradient를 유발하여 빠른 training을 가능하게 한다.
1. Introduction
지난 10년동안 DeepLearning은 Computer Vision, Speech Recognition, Machine Translation, Game-playing 등 다양한 어려운 작업에서 진전을 이루어왔다. 이러한 진전은 HW, 데이터셋, 알고리즘, 아키텍쳐 측면의 발전과 함께 해왔다.
그러한 진전 중 가장 두드러진 예는 Batch Norm이다.
High Level에서, BatchNorm은 Layer 입력의 distribution을 안정화 시켜 training을 향상시키는 것을 목표로 한다.
이는 입력의 Mean과 Variance의 분포를 제어하는 추가 Netwrok Layer를 도입함으로써 달성된다.
Batch Norm은 6,000개 이상의 연구에서 성공적으로 사용되었고 논쟁의 여지가 없다.
그럼에도, Batch Norm의 효과가 어디에서 비롯되는지 잘 이해하지 못하고 있다.
현재 가장 널리 받아들여진 설명은 "내부 공변량 shift"(ICS)과 관련이 있다는 것이다.
ICS는 앞선 layer 의 update에 의해 야기되는 입력분포의 변화가 training에 부정적인 영향을 준다고 추측한다.
Batch Norm의 목표는 ICS를 감소시켜 이런 효과를 개선시키는 것이었습니다.
이러한 이론이 다수설임에도 불구하고 구체적인 증거가 없다.
이 논문의 주요 목표는 이러한 단점을 해결하는 것이다.
Our Contributions.
출발점은 Batch Norm와 ICS 사이의 연관이 없다는 것이 보이는 것이다.
우리는 Batch Norm와 ICS 를 감소시키지 않을 수 있다는 것을 발견했다.
우리는 Batch Norm이 Optimization Problem을 smooth하게 만든다는 것을 입증한다.
이는, Gradients가 더 예측 가능함을 보장하며, 이를 통해 더 많은 범위를 학습하고, 더 빠른 네트웤 통합을 가능하게 한다.
자연 조건 하에서 Batch Norm이 적용된 모델의 loss과 gradients의 Lipschitzness(β-smoothness)가 개선 된다는 것을 증명한다.
마지막으로, Smoothening이 Batch Norm과 고유하게 연결되어있지 않음을 보여준다.
Section 2에서는 Batch Norm과 최적화, ICS 사이의 연결점을 찾아낸다.
Section 3에서는 Batch Norm의 DNN에서 성공한 근원을 분석한다.
Section 4에서는 이론적 분석을 제시한다
Section 5에서 추가적 작업을 논의하고
Section 6에서 결론을 내린다.
2. Batch normalization and internal covariate shift
광의의 Batch Norm은 mini-batch를 통해 입력을 안정화하는 것을 목표로 한다.
이는 mean과 variance를 설정하는 layer를 추가시킴으로써 달성된다.
활성화는 각각 0(mean)과 1(variance) 이다.
이는 non-linear func. 이전에 적용된다
Batch Norm 개발의 주요 동기는 ICS의 감소였다. ICS의 감소 원인이 Batch Norm이라고 널리 알려져왔다.

의문점
1) BatchNorm이 실제 ICS와 관련 있는가?
2) BatchNorm으로 입력 안정화가 ICS 감소에 효과적인가?
2.1 Does BatchNorm’s performance stem from controlling internal covariate shift?
실험 1. BatchNorm 다음 Random Nosie를 주입하여 훈련. (Appendix A 참조)
- Random Noise는 ICS의 이동을 발생시킨다.
- 따라서 매 입력 계층은 서로 다른 입력 분포를 가진다
- 이에 따른 분포 불안정성의 영향을 측정한다.


Cos Angle, L2-diff 가 평균과 분산.. ? 왜요 ..? ㅠㅠㅠ 모르겠어요
이러한 결과는 Batch Norm의 성능이득이 입력의 안정성 증가에서 비롯된다는 주장과 일치하기 어렵다.
2.2 Is BatchNorm reducing internal covariate shift?
2.1의 연구 결과는 ICS가 Training Perfomance와 직접 연관되어 있지 않음을 분명히 한다.
- ICS를 포함하는 더 넓은 개념이 있는가? BatchNorm은 그 개념을 줄였는가?
parameter update가 ICS를 제공한다.? Ioffe & Szegedy
- 이 질문에 답하기 위해 ICS를 포함하는 더 넓은 개념을 고려한다. Training은 1차 미분이기 때문에 loss의 gradients가 적당하다. 우리는 layer의 update 전후의 gradients의 difference를 측정한다.
아래 식으로 정의한다
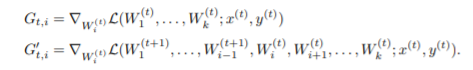
W : 파라미터 of k개의 layer
x,y : input-label pair
t : time
ICS : || G_t,i - G'_t,i || _2
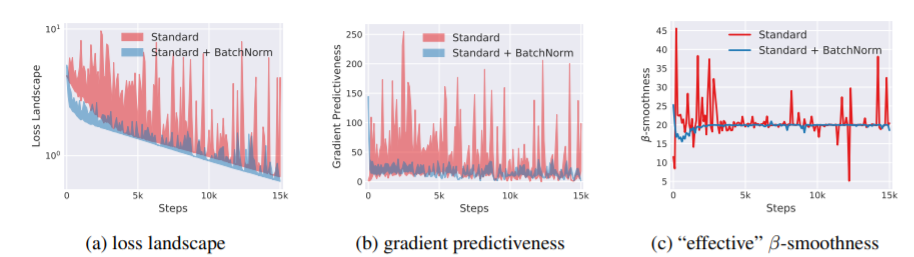
(a) : variation in loss
(b) : l2 changes in gradient
(c) : β-smoothness
위 3건에 대해서 모두 성능이 개선됨을 알 수 있다.
이 결과는 Section 4에서 다시 언급 된다.
G와 G'의 차이를 구함으로써 정밀하게 포착한다.
gradient stochasticity 뿐만 아니라 non-linear의 영향을 분리하기 위해 Appendix A에서 DLN(25-layer)에 대해서도 분석을 수행한다.
전통적인 Batch Norm의 이해는 G와G'의 상관관계를 증가시켜 ICS를 감소시킬 것을 제안한다.
우리는 Batch Norm이 있을 때 ICS의 증가 경우가 많다고 관찰한다.
DLN에서 특히 두드러진다. 이런 결과는 Optimize 관점에서 Batch Norm이 ICS를 줄이지 않을 수 있음을 시사한다.
최적화와 ICS는 연관성이 크지 않다.
그런데 Batch Norm은 최적화에 영향을 주고 있다. 왜?
3.1 The smoothing effect of BatchNorm
Batch Norm은 landscape를 더 smooth 하게 만든다.
첫번째 , loss 함수의 Lipschitzness 개선이다.
- loss 와 gradient의 변화를 작게 만든다.
- 효과적인 β-smoothness 를 만든다.
이 이유를 이해하려면 non-batchnorm의 DNN에서 loss function은 convex도 아니고, 꼬임,평탄지역, 뾰족한 minima 가 있다는 것을 떠올리세요.
batch norm이 아니면 non-convex 한가요 ..?
=> Batch Norm으로 Reparametrization으로 gradient의 신뢰성과 예측성을 높여줌.
Lipschitzness 이 개선 되면서, larger step으로 gradient를 이동할 때 추정치의 신뢰성이 향상.
따라서 sudden change, flat region, sharp local minimum 으로 빠질 위험이 없음.
이것이 학습속도를 빠르게 만들고, 하이퍼 파라미터 선택에 덜 민감하게 만듬.
3.2 Exploration of the optimization landscape
1. 매 step에서 loss의 gradient를 계산하고 변화량을 측정 Fig.(a)
2. 주어진 점의 loss grad와 지나온 방향에 따른 L2 를 측정 Fig.(b)
3. β-smoothness 표시. Fig.(c)
linear에 대해서도 고려했다 Appendix B의 Fig 9와 12를 봐라.
마지막으로, 구배방향과 손실 형태에 대해 초점을 두었지만, 랜덤 방향으로 검토할 때도 비슷하게 작용한다는 것을 강조한다.
3.3 Is BatchNorm the best (only?) way to smoothen the landscape?
- 이러한 smoothing이 Batch Norm의 고유한 특징인가?
- 다른 Norm 을 이용해서 유사한 효과를 얻을 수 있는가?
(다른 norm의 경우 gaussian 분포가 아니다. fig 14 참조)
- 따라서 p-norm을 이용한 정규화는 moment의 control과 stability를 보장하지 않는다.
- 결과는 Appendix B의 11,12,13을 봐라
- 그치만 우리는 Norm 전략이 Batch Norm 같은 성능을 제공한다고 본다.
- 실제로 DNN의 경우 L1-Norm은 Batch Norm보다 더 우수한 성능을 발휘한다.
- Appendix B의 11,12보면 Norm 기법이 비슷하게 smooth 한거 준다.
4 Theoretical Analysis
- Batch Norm이 Optimization에 영향을 주는 것을 시사했다.
- 이제 이론적으로 탐구한다.
- 이를위해 linear 한 DNN을 고려한다.
4.1 Setup
- Batch Norm Layer를 추가하는 것의 영향을 분석한다.
- FC layer 뒤에 BN을 삽입하여 optimization landscape를 비교한다.

weight : W_ij
L : loss function
L hat : normalized loss function
input x
input y = Wx
y hat : whitened version of y ( std : mean 0, var 1)
z = gamma * y_hat + beta
4.2 Theoretical Results
- y_j를 최적화 하는 것을 고려한다
- BN으로 Lipschitz-cont , 예측가능한 grad 를 알 수 있다.
- 그리고 BN된 landscape가 weight landspace의 바람직한 최악으로 해석됨을 보여준다.
- y_j 의 grad 를 본다. lipschitz 상수가 손실 변경량을 제어하므로 최적화에 중요한 역할을 한다.
- BN이 더 나은 lipschitz 상수를 보인다는것을 보여준다.
- grad 분산의 평균이 0 을 벗어나거나, grad와 act가 연관있어도 lipschitz 상수는 현저히 감소한다.
- 이러한 감소는 부가적이며, BN결과가 원래와 스케일이 동일하더라도 효과가 있다.
Theorem 4.1

<> : inner product
last term은 0에서 벗어날 것으로 예상.
sigma로 나누면서 커짐.
gamma/sigma 로 'flatness' 해짐.
Theorem 4.2
2차 미분적 특성
- BN이 추가되었을 때 Hessian은 mini-batch에 의해 input variance가 rescale 되고, additive facotr에 의해서 감소(smoothness 증가). 이를 통해 1st-order term이 더 예측 가능함.

Hessian은 loss가 locally convex 할 경우 PSD 이며, 마지막 레이어에서 convex loss가 있고 국소적으로 linear act한 DNN에 해당된다. (e.g. softmax , other loss).
- grad y_hat_j 가 min loss를 가리키는한 <y_hat_j, y_hat_i> >0 조건을 만족한다.
이로써 Batch Norm은 더욱더 예측가능하게 step을 이동한다.
Observation 4.3
어떠한 input X 와 네트워크 W에 대해 gamma=sigma 일때 BN Config는 동일한 result y_hat을 내놓는다.
따라서 landscape의 min은 BN landscape에 보존된다.
이제부터 최악의 상황으로 해석할 것이다.
Theorem 4.4
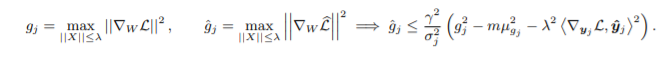
Lemma 4.5

W : local optima in BN
<W,W*> >0 일 때 W들은 optima에 가깝다.
5. Related Work
- BN의 대안으로 「Layer 정규화」, 「Batch Subset」, 「이미지 차원」 등 많은 표준화가 제안되었다.
- Weight Norm 은 Activation 대신 Weight를 정규화 하는 보완 방식이다.
- ELU와 SELU는 BN의 대안으로 사용할 수 있는 사례이다.
이런 기법들은 개선된 효과를 제공하지만 BN을 설명하지는 않는다.
BN은 파라미터 초기화를 최적화하는 경향을 지닌다.
w/o BN 모델은 grad와 활성함수 사이에 작은 correlation을 가진다.
6. Conclusions
본 연구는 DNN에서 BN 효과의 근원을 연구했다.
- BN과 ICS는 크게 관계 없다는 것을 입증한다.
- 대신 BN이 loss의 관점에서 안정적이고 smooth 하게 optimization을 한다.
- 이로써 빠르고 효과적이고 예측 가능한 최적화가 실행된다.
- 그리고 이러한 효과는 BN에만 국한되지 않으며, 다른 normalization도 유사한 효과를 내는 것을 볼 수 있다.
'AI > DL' 카테고리의 다른 글
| [Fast.Ai] FaceBook Fast.Ai Kr Study #1 (0) | 2020.08.30 |
|---|---|
| [Fast.Ai] FaceBook Fast.Ai Kr Study #OT (0) | 2020.08.18 |